Trong thời gian gần đây, lĩnh vực Trí Tuệ Nhân Tạo (AI) đã chứng kiến sự đổi mới đáng kể, đặc biệt là với sự ra đời của các mô hình sáng tạo dạng khuếch tán. Tuy nhiên, việc tạo ra âm thanh với độ dài linh hoạt vẫn là một thách thức. Nhằm giải quyết vấn đề này chính là lý do tại sao Stable Audio ra đời, công cụ tạo nhạc mới ra bởi Stability AI - công ty đã làm ra Stable Diffusion.
Chúng ta sẽ tìm hiểu về Stable Audio, cách hoạt động, cách sử dụng cũng như một số tính năng chính của công cụ này
Nếu bạn quan tâm đến Khóa học sử dụng AI để tạo VIDEO thì tham khảo TẠI ĐÂY
Stable Audio là gì?
Trước tiên, ta hãy điểm qua các tính năng chính của Stable Audio:
- Tạo âm thanh/nhạc chất lượng cao tùy ý với độ dài tùy chọn lên đến 45 giây (44.1 kHz stereo).
- Mỗi lần bạn tạo một tệp âm thanh bằng Stable Audio, mô hình Trí Tuệ Nhân Tạo AI sẽ tạo ra một file độc đáo khác nhau Bạn sẽ không bao giờ nhận được cùng một đoạn âm thanh hai lần.
- Bạn có thể sử dụng Stable Audio để tạo ra âm nhạc gốc để sử dụng trong các dự án của bạn và trong các dự án thương mại nếu bạn là người dùng Pro, hoặc trong các dự án không thương mại nếu bạn là người dùng gói Miễn phí (Free/Basic).
Một số khác biệt giữa Mô hình biến đổi (Transformer Model) được sử dụng trong MusicGen và Mô hình khuếch tán (Diffusion Model) được sử dụng trong Stable Audio:
Mô hình biến đổi (Transformer Model):
- Cách hoạt động: Sử dụng kiến trúc tự học và xử lý dữ liệu song song mà không cần bước lặp lại.
- Ứng dụng: Thường được sử dụng trong xử lý ngôn ngữ tự nhiên và các ứng dụng liên quan đến ngôn ngữ.
- Đặc điểm: Hiệu quả trong việc giải quyết nhiều vấn đề phức tạp trong xử lý ngôn ngữ tự nhiên.
Mô hình khuếch tán (Diffusion Model):
- Cách hoạt động: Sử dụng nhiều bước lặp lại để xử lý dữ liệu và tạo ra các mẫu độc đáo.
- Ứng dụng: Thường được sử dụng trong lĩnh vực sáng tạo như tạo hình và tạo âm thanh.
Đặc điểm: Tạo ra các mẫu sáng tạo và đa dạng
Tuy nhiên, khi nói đến việc tạo âm thanh, một thách thức độc đáo nảy sinh. Hầu hết các mô hình khuếch tán được đào tạo để tạo ra đầu ra cố định, khiến cho chúng ít linh hoạt trong việc tạo âm thanh. Ví dụ, một mô hình khuếch tán âm thanh được đào tạo trên các đoạn âm thanh có thời lượng 30 giây chỉ có thể tạo ra âm thanh trong các đoạn có thời lượng 30 giây. Hạn chế này trở nên rõ ràng khi ta muốn tạo âm thanh có độ dài đa dạng ví dụ như một cả một bài nhạc dài.
Stable Audio đem lại sự kiểm soát chính xác đối với nội dung và độ dài của âm thanh mà bạn muốn sáng tạo. Mô hình Stable Audio (stable-audio-audiosparx-v1-0) sử dụng kỹ thuật downsampling (nén mạnh) âm thanh, nhờ đó giúp tạo ra âm thanh một cách nhanh chóng. Đây là một nền tảng đột phá sử dụng một kiến trúc mô hình khuếch tán tiềm ẩn, được bổ sung bởi thông tin văn bản, thời lượng và thời gian bắt đầu của tệp âm thanh. Phương pháp tiếp cận này mang lại cho người dùng sự kiểm soát chính xác đối với nội dung và độ dài của âm thanh được tạo ra.
Stable Audio tận dụng sức mạnh của việc thể tiềm tàng của âm thanh được nén mạnh, giúp tăng tốc độ suy luận so với âm thanh nguyên bản. Sử dụng các kỹ thuật lấy mẫu khuếch tán tiên tiến nhất, mô hình Stable Audio có thể tạo ra âm thanh 95 giây stereo với tần số lấy mẫu 44.1 kHz trong thời gian chỉ trên một giây bằng GPU NVIDIA A100.
Thông tin Kỹ thuật

Cơ sở của Stable Audio là việc sử dụng mô hình biến thể tự động (VAE) để nén và tạo ra âm thanh. Bằng cách này, thông tin văn bản được kết hợp để tạo ra âm thanh dựa trên mối quan hệ văn bản-âm thanh. Thời gian cũng được sử dụng để xác định độ dài của âm thanh, tạo điều kiện cho sự linh hoạt trong sáng tạo.
- Chúng tôi áp dụng mô hình biến thể tự động (VAE) để nén âm thanh.
- Sử dụng thông tin văn bản để tạo ra âm thanh dựa trên mối quan hệ văn bản-âm thanh.
- Sử dụng thời gian để xác định độ dài của âm thanh.
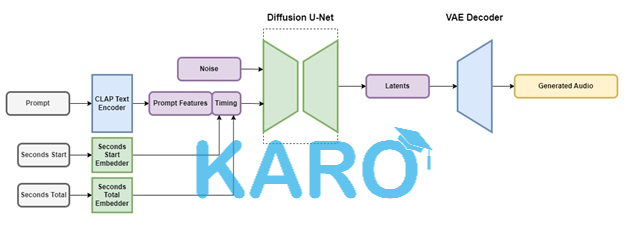
Tại trung tâm của Stable Audio là các mô hình Stable Audio, bao gồm một số thành phần quan trọng như bộ mã hóa biến thể (VAE), bộ mã hóa văn bản và mô hình khuếch tán được điều kiện dựa trên U-Net.
VAE đóng một vai trò quan trọng trong việc nén âm thanh stereo thành một mã hóa tiềm ẩn bị nén dữ liệu, chống nhiễu và có khả năng nghịch đảo. Mã hóa này không chỉ tạo điều kiện cho việc tạo ra và đào tạo nhanh hơn, mà còn tăng cường sự chắc chắn của mô hình khi làm việc với các mẫu âm thanh nguyên bản. Một kiến trúc đầy đủ của lớp, lấy cảm hứng từ các kiến trúc mã hóa và giải mã của Descript Audio Codec: https://github.com/descriptinc/descript-audio-codec , cho phép mã hóa và giải mã âm thanh có độ dài tùy ý, đồng thời cung cấp đầu ra chất lượng cao.
Để giới thiệu việc điều kiện dựa trên văn bản vào mô hình, trình mã hóa văn bản đóng băng của một mô hình CLAP: https://github.com/LAION-AI/CLAP được sử dụng, được đào tạo từ đầu trên tập dữ liệu. Phương pháp này trang bị các đặc trưng văn bản với thông tin giá trị về mối quan hệ phức tạp giữa từ ngữ và âm thanh. Các đặc trưng văn bản này, trích xuất từ lớp trước cùng của trình mã hóa văn bản CLAP, hướng dẫn U-Net dựa trên khuếch tán thông qua các lớp chú ý chéo
Hơn nữa, Stable Audio sử dụng nhúng thời gian dựa trên dữ liệu đào tạo để tinh chỉnh quá trình tạo âm thanh. Những nhúng này bao gồm thông tin về thời điểm bắt đầu của một đoạn âm thanh cụ thể (được gọi là “seconds_start”) và tổng thời gian của tệp âm thanh gốc (được gọi là “seconds_total”). Ví dụ, nếu bạn lấy một đoạn âm thanh 30 giây từ một tệp âm thanh 80 giây, bắt đầu từ 0:14, thì "seconds_start" là 14 và "seconds_total" là 80. Những giá trị này được chuyển đổi thành các nhúng được học qua từng giây và nối với các biểu tượng gợi ý trước khi được truyền vào các lớp chú ý chéo của U-Net. Trong quá trình suy luận, những giá trị này được cung cấp cho mô hình như thông tin điều kiện, cho phép người dùng chỉ định độ dài tổng thể của âm thanh đầu ra.
Mô hình khuếch tán cho Stable Audio là một U-Net có 907 triệu tham số, dựa trên mô hình được sử dụng trong Moûsai: https://arxiv.org/abs/2301.11757 . Nó sử dụng sự kết hợp của các lớp dư thừa, các lớp tự chú ý và các lớp chú ý chéo để giảm độ ồn đầu vào dựa trên thông tin văn bản và thông tin thời gian. Việc triển khai chú ý hiệu quả về bộ nhớ được thêm vào U-Net để cho phép mô hình mở rộng hiệu quả hơn đối với độ dài chuỗi dài hơn.
Dữ Liệu Training
Stable Audio (stable-audio-audiosparx-v1-0) sử dụng một khối lượng lớn dữ liệu training bao gồm hơn 800,000 tệp âm thanh và dữ liệu văn bản từ AudioSparx - một thư viện âm nhạc và trang web hàng đầu về âm thanh cổ điển. Điều này đảm bảo rằng chất lượng âm nhạc bạn tạo ra và phù hợp với việc sử dụng thương mại.
Mô Hình Mã Nguồn Mở và Các Dự Án trong Tương lai
Stable Audio đại diện cho những nghiên cứu tiên tiến về tạo âm thanh do phòng thí nghiệm nghiên cứu âm thanh tạo hình của Stability AI, Harmonai, thực hiện. Stability AI sẽ liên tục cải thiện kiến trúc
mô hình, tập dữ liệu và quy trình đào tạo để nâng cao chất lượng sản phẩm đầu ra, khả năng điều khiển, tốc độ suy luận và độ dài đầu ra.
Ngoài ra, dự án này đã được đào tạo hoàn toàn trên một bộ dữ liệu thương mại được cấp phép từ AudioSparx, vì vậy có thể được sử dụng cho mục đích thương mại dựa trên giấy phép đã thỏa thuận với họ. Stability AI đang xây dựng phiên bản tập dữ liệu dataset mở và sẽ phát hành cùng với bộ training vv. theo như đã đề cập trong blog nghiên cứu. Stability AI sẽ tiếp tục cải tiến nền tảng và tính năng để bạn có thể điều chỉnh mô hình của riêng bạn, tạo video âm nhạc và nhiều tính năng khác trong tương lai. Hãy chú ý đến các phiên bản mới sắp tới từ Harmonai.
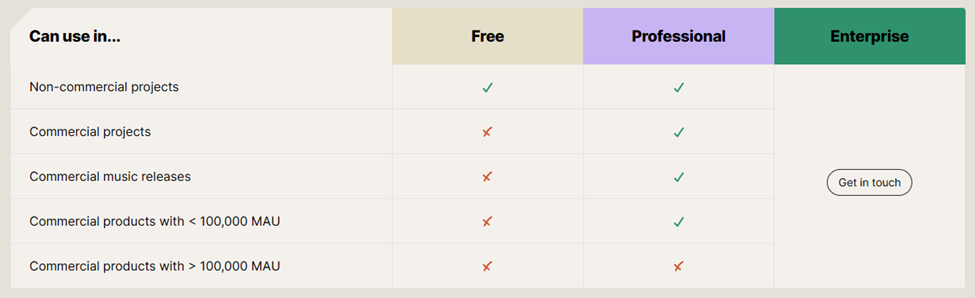
Gói Sử Dụng Miễn Phí và Thương Mại
Gói Miễn phí (Free/Basic):
- Số lượng bản nhạc có thể tạo hàng tháng: 20
- Thời lượng bản nhạc: Lên đến 45 giây
- Giấy phép: Sử dụng cho mục đích phi thương mại
Gói Chuyên nghiệp (Professional) - $11.99 mỗi tháng (chưa bao gồm VAT/thuế bán hàng)
- Số lượng bản nhạc có thể tạo hàng tháng: 500
- Thời lượng bản nhạc: Lên đến 90 giây
- Giấy phép: Sử dụng cho mục đích thương mại
Gói Doanh nghiệp (Enterprise)- Số lượng và Giá tùy chỉnh (cần liên hệ)
- Số lượng tạo bản nhạc hàng tháng: Tùy chỉnh
- Thời lượng bản nhạc: Tùy chỉnh
- Giấy phép: Sử dụng cho mục đích thương mại
Cách sử sụng Stable Audio
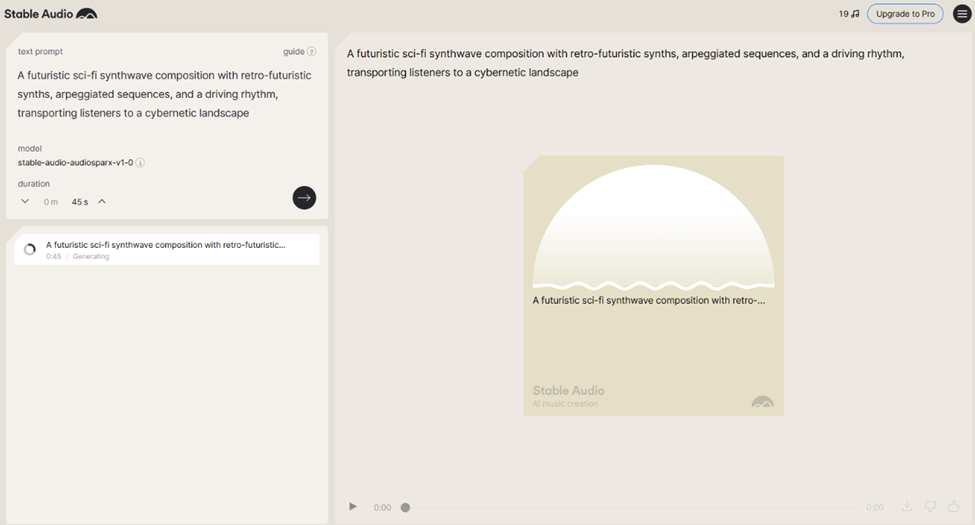
1. Làm thế nào để tôi sử dụng Stable Audio?
- Đơn giản! Bạn chỉ cần đăng ký tài khoản và trải nghiệm công cụ này bằng cách truy cập: https://www.stableaudio.com và điền lệnh prompt tùy ý để tạo nhạc.
2. Tôi có thể sử dụng âm thanh được tạo ra cho các dự án thương mại không?
- Bạn có thể sử dụng âm thanh trả phí cho các dự án thương mại (với gói Pro and Enterprise).
3. Tôi có thể tự train mô hình của riêng tôi không?
- Stability AI trong thời gian tới sẽ giới thiệu các mô hình mã nguồn mở để bạn có thể tự train.
Tạo lệnh Prompt Sáng Tạo
Stable Audio cung cấp các gợi ý sáng tạo để bạn có thể khám phá tiềm năng của mình với trí tuệ nhân tạo. Dưới đây là một số mẹo:
- Thêm Chi Tiết: Hãy bao gồm các thông tin cụ thể trong hướng dẫn của bạn. Thể loại, mô tả, nhạc cụ và tâm trạng đều đóng một vai trò quan trọng.
Ví dụ: Cinematic, Soundtrack, Wild West, High Noon Shoot Out, Percussion, Whistles, Horses, Action Scene, SFX, Shaker, Guitar, Bass, Timpani, Strings, Tense, Climactic, Atmospheric, Moody
- Đặt Tâm Trạng: Khi bạn mô tả tâm trạng mong muốn, hãy thử kết hợp các thuật ngữ âm nhạc và cảm xúc.
Ví dụ: groovy, rhythmic
- Chọn Nhạc Cụ: Sử dụng tính từ trong tên nhạc cụ để mô tả chính xác.
Ví dụ: Reverberated Guitar, Powerful Choir, or Swelling Strings
- Đặt BPM: Điều chỉnh số nhịp mỗi phút để tạo ra nhịp điệu âm thanh mong muốn.
Ví dụ: 170 BPM
- Âm Thanh Hoàn Chỉnh: Sử dụng Stable Audio để tạo ra âm thanh hoàn chỉnh với nhiều nhạc cụ.
Ví dụ:
- Trance, Ibiza, Beach, Sun, 4 AM, Progressive, Synthesizer, 909, Dramatic Chords, Choir, Euphoric, Nostalgic, Dynamic, Flowing
- Calm meditation music to play in a spa lobby
-Nhịp Riêng Lẻ: Bạn cũng có thể sử dụng Stable Audio để tạo ra các bản âm thanh Nhịp riêng lẻ.
Ví dụ:
- Electric guitar top line solo instrumental, no drums, Classic Rock, 105 BPM, Grade: Featured, Instruments: Guitar
- Samba percussion
- Drum solo
- Âm Thanh Hiệu Ứng: Stable Audio cũng có khả năng tạo ra âm thanh hiệu ứng.
Ví dụ: Ringtone, Explosion, Car passing by; Fireworks; 44.1k high fidelity