6 chuyên gia hàng đầu tiết lộ bí quyết hơn 1 năm xây dựng thành công ứng dụng thực tế với mô hình ngôn ngữ lớn (LLM) [Phần 1]
Trong thế giới công nghệ đang bùng nổ hiện nay, các mô hình ngôn ngữ lớn (LLM) đang mở ra vô vàn cơ hội phát triển ứng dụng thực tế. Tuy nhiên, con đường từ ý tưởng đến sản phẩm hoàn chỉnh không hề dễ dàng. Làm thế nào để vượt qua những thách thức và xây dựng hệ thống LLM đạt chuẩn sản xuất? Bài viết này tập trung vào các lời khuyên thực tiễn, không rườm rà về việc xây dựng các hệ thống LLM trong thực tế.
Hãy khám phá bí quyết từ 6 chuyên gia hàng đầu: Eugene Yan (Amazon), Bryan Bischof (Hex), Charles Frye (Modal), Hamel Husain (Tư vấn độc lập), Jason Liu (Tư vấn ML) và Shreya Shankar (UC Berkeley). Họ đã trực tiếp "cầm cương" trong hành trình chinh phục LLM suốt một năm qua. Từ những bài học quý giá đến các mẹo thực tiễn, bạn sẽ tìm thấy chìa khóa để mở cánh cửa thành công.
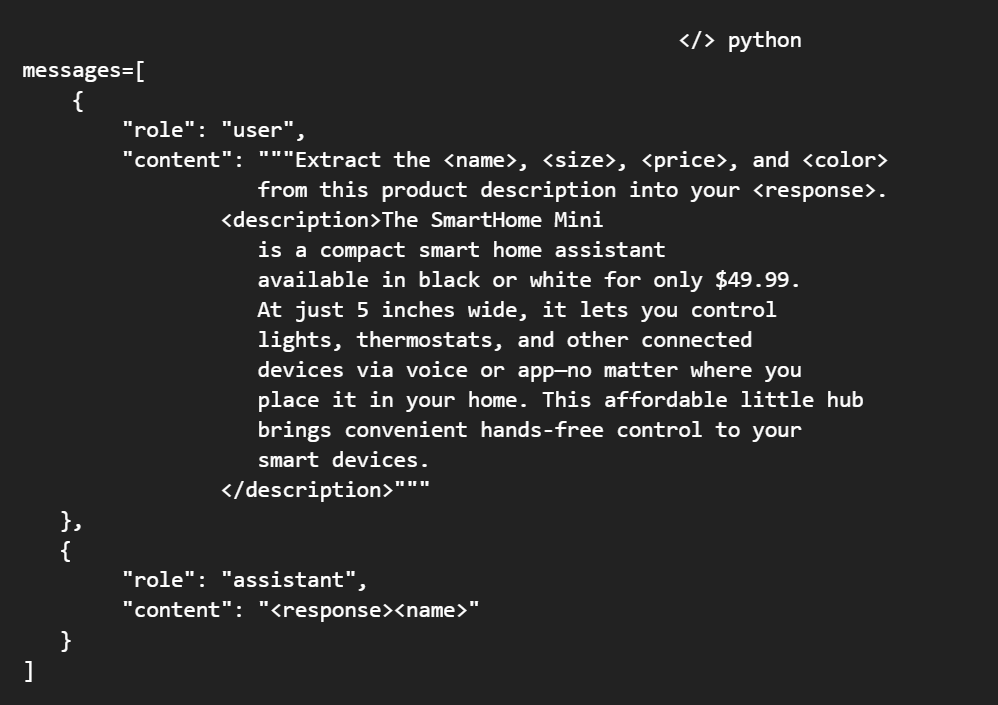
Trước tiên, hãy làm chủ nghệ thuật "thôi miên" mô hình với các kỹ thuật tạo lời nhắc (prompting) hiệu quả:
-Sử dụng ít nhất 5 mẫu (n-shot) để tránh mô hình tập trung quá mức vào các ví dụ cụ thể. Đừng ngại thử với 12, 24 hoặc thậm chí 36 mẫu. Các mẫu nên đại diện cho phân phối đầu vào dự kiến.
-Cung cấp đầu ra mong muốn. Trong nhiều trường hợp, chỉ cần các mẫu đầu ra mà không cần cặp đầu vào-đầu ra đầy đủ. Việc cung cấp các ví dụ đầu ra mong muốn đôi khi là đủ.
-Kết cấu hóa đầu vào/đầu ra bằng cách thêm siêu dữ liệu. Sử dụng XML (Claude) hoặc Markdown/JSON (GPT) để hướng dẫn mô hình xử lý đầu vào và tạo đầu ra mong muốn một cách đáng tin cậy hơn.
-Chia nhỏ các lời nhắc phức tạp. Mỗi lời nhắc nên thực hiện tốt một việc, tương tự nguyên tắc trách nhiệm duy nhất trong lập trình. Thay vì một siêu lời nhắc, hãy tạo nhiều lời nhắc tập trung.
-Sử dụng chain-of-thought (CoT) prompting để giảm ảo giác, yêu cầu LLM giải thích suy luận trước khi đưa ra câu trả lời cuối cùng.
Nếu sử dụng LLM hỗ trợ sử dụng công cụ, các mẫu n-shot cũng nên sử dụng các công cụ mà bạn muốn tác tử sử dụng.
Đừng quên "bùa chú" quan trọng: cung cấp ngữ cảnh phù hợp thông qua truy xuất và tạo (RAG):
-Chất lượng của RAG phụ thuộc vào mức độ liên quan (đo bằng MRR, NDCG), mật độ thông tin và mức độ chi tiết của tài liệu được truy xuất.
-Kết hợp tìm kiếm theo từ khóa (như BM25) và tìm kiếm theo embedding. Từ khóa hiệu quả cho các truy vấn cụ thể (tên, từ viết tắt, ID), trong khi embedding tốt cho tính tương đồng ngữ nghĩa và đa phương thức. Tìm kiếm theo từ khóa thường hiệu quả hơn về mặt tính toán.
-Ưu tiên RAG hơn tinh chỉnh (fine-tuning) khi cần bổ sung kiến thức mới. RAG linh hoạt, dễ cập nhật, rẻ hơn và cho phép cô lập dữ liệu cho từng khách hàng. Nghiên cứu gần đây cho thấy RAG có thể vượt trội hơn cả tinh chỉnh.
-Ngay cả khi cửa sổ ngữ cảnh tăng lên (như 10M token của Gemini 1.5), RAG vẫn sẽ hữu ích để chọn lọc thông tin phù hợp và tránh chi phí tính toán lớn.
-Cung cấp thêm mô tả cột và các giá trị đại diện trong ngữ cảnh có thể giúp LLM hiểu ngữ nghĩa của bảng dữ liệu tốt hơn và tạo ra các truy vấn SQL chính xác hơn.
Tiếp theo, hãy "đúc" nên quy trình làm việc hoàn hảo:
-Tập trung vào các kế hoạch tác tử xác định để đảm bảo độ tin cậy. Với mục tiêu cấp cao, tác tử tạo kế hoạch và thực thi một cách xác định. Điều này giúp kiểm thử, gỡ lỗi dễ dàng hơn và có thể truy vết lỗi đến các bước cụ thể.
-Thu thập các kế hoạch đã tạo để cải thiện lời nhắc hoặc tinh chỉnh tác tử trong tương lai. Các kế hoạch có thể được biểu diễn dưới dạng đồ thị có hướng không chu trình (DAG).
-Tránh tăng nhiệt độ để tạo sự đa dạng đầu ra. Thay vào đó, hãy xáo trộn thứ tự mục, thay đổi nhẹ lời nhắc, giữ danh sách các đầu ra gần đây để tránh lặp lại, hoặc thay đổi cách diễn đạt trong lời nhắc.
-Chia nhỏ các tác vụ phức tạp thành các bước đơn giản hơn. Ví dụ, trong dự án AlphaCodium, quy trình bao gồm suy ngẫm về vấn đề, lập luận về các bài kiểm tra công khai, tạo ra các giải pháp khả thi, xếp hạng các giải pháp, tạo ra các bài kiểm tra tổng hợp và lặp lại trên các giải pháp.
-Các tác vụ nhỏ với mục tiêu rõ ràng sẽ tạo nên các lời nhắc tác tử hoặc lời nhắc quy trình tốt nhất. Mặc dù không bắt buộc phải luôn yêu cầu đầu ra có cấu trúc trong mọi lời nhắc tác tử, nhưng đầu ra có cấu trúc sẽ giúp tích hợp dễ dàng hơn với hệ thống điều phối tương tác của tác tử với môi trường.
-Sử dụng caching để tiết kiệm chi phí, loại bỏ độ trễ tạo và giảm rủi ro nội dung không phù hợp nếu câu trả lời đã được kiểm duyệt trước đó.
-Cân nhắc tinh chỉnh (fine-tuning) khi lời nhắc không đủ để đạt được đầu ra chất lượng cao đáng tin cậy. Tuy nhiên, hãy cân nhắc giữa chi phí và lợi ích, vì tinh chỉnh đòi hỏi dữ liệu có chú thích, huấn luyện, đánh giá và tự lưu trữ mô hình.
Cuối cùng, hãy trở thành "người gác cổng" đáng tin cậy bằng cách đánh giá và giám sát chặt chẽ:
-Tạo các bài kiểm thử đơn vị dựa trên mẫu đầu vào/đầu ra thực tế. Bắt đầu với các khẳng định về cụm từ cần có/loại trừ và kiểm tra số lượng từ/mục/câu nằm trong một khoảng nào đó.
-Sử dụng LLM làm "trọng tài" bằng cách so sánh từng cặp thay vì chấm điểm một mẫu duy nhất. Kiểm soát thiên vị vị trí bằng cách hoán đổi thứ tự cặp, cho phép hòa, sử dụng CoT và kiểm soát độ dài câu trả lời.
-Đơn giản hóa gán nhãn bằng cách cho phép gán điểm nhị phân (có/không) hoặc so sánh từng cặp. Điều này giúp thu thập chú thích nhanh hơn, nhất quán hơn so với thang Likert.
-Xây dựng các rào cản để lọc nội dung không phù hợp, độc hại. Sử dụng API kiểm duyệt nội dung và các công cụ phát hiện thông tin nhận dạng cá nhân (PII).
-Xử lý vấn đề ảo giác bằng cách kết hợp kỹ thuật tạo lời nhắc (như CoT) và các rào cản đánh giá tính nhất quán, đồng thời sử dụng RAG để nắm bắt thông tin một cách xác định.
-Tránh quá nhấn mạnh vào một số phép đánh giá nhất định (như Needle-in-a-Haystack) vì điều này có thể dẫn đến hiệu suất tổng thể thấp hơn.
-Sử dụng sản phẩm của chính mình ("dogfooding") để có cái nhìn sâu sắc về các điểm yếu trên dữ liệu thực tế và thu thập các mẫu sản xuất có thể chuyển thành phép đánh giá.
-Đánh giá không tham chiếu (reference-free evaluation) và các rào cản (guardrails) có thể được sử dụng thay thế cho nhau trong một số trường hợp, chẳng hạn như đánh giá tóm tắt hoặc dịch thuật.
Điều quan trọng là phải không ngừng thử nghiệm, lặp lại và học hỏi trong quá trình xây dựng các hệ thống LLM. Đây là một lĩnh vực còn khá mới mẻ và đang phát triển nhanh chóng, vì vậy việc liên tục cập nhật kiến thức và điều chỉnh các phương pháp tiếp cận là rất cần thiết.
Với những bí quyết này trong tay, bạn đã sẵn sàng để chinh phục thế giới LLM và kiến tạo những ứng dụng tuyệt vời. Hãy can đảm bước ra khỏi vùng an toàn, không ngừng thử nghiệm và học hỏi. Thành công đang chờ đón những ai dám ước mơ và hành động.
Chúc bạn một hành trình thú vị và đầy thành tựu trên con đường trở thành "bậc thầy" của LLM!
Theo OREILLY