
Mô hình Sora của OpenAI đã khiến cả thế giới phải kinh ngạc bởi khả năng tạo ra những video cực kỳ chân thực về nhiều cảnh khác nhau. Dưới đây là video do OpenAI phát hành thể hiện khả năng của mô hình.
Trong bài đăng trên blog này, chúng tôi đi sâu vào một số chi tiết kỹ thuật đằng sau Sora. Chúng tôi cũng nói về suy nghĩ hiện tại của mình xung quanh ý nghĩa của những mô hình video này. Cuối cùng, chúng tôi thảo luận suy nghĩ của mình về điện toán được sử dụng cho các mô hình đào tạo như Sora và đưa ra các dự đoán về cách so sánh điện toán đào tạo đó với suy luận, điều này có những dấu hiệu có ý nghĩa về nhu cầu GPU ước tính trong tương lai.
Những phát hiện chính từ báo cáo này được tóm tắt dưới đây:
Sora là một mô hình khuếch tán được xây dựng dựa trên Biến áp khuếch tán (DiT), Khuếch tán tiềm ẩn và dường như mở rộng đáng kể cả mô hình và tập dữ liệu huấn luyện.
Sora chứng minh rằng việc mở rộng quy mô các mô hình video là đáng giá và việc mở rộng quy mô hơn nữa, tương tự như Mô hình ngôn ngữ lớn (LLM), sẽ là động lực chính giúp các mô hình cải tiến nhanh chóng.
Các công ty như Runway, Genmo và Pika đang nỗ lực xây dựng giao diện và quy trình làm việc trực quan xung quanh các mô hình tạo video như Sora. Điều này sẽ xác định mức độ hữu ích và khả năng sử dụng rộng rãi của chúng.
Sora cần một lượng sức mạnh tính toán khổng lồ để đào tạo, ước tính khoảng 4.200-10.500 GPU Nvidia H100 trong 1 tháng.
Để suy luận, chúng tôi ước tính rằng Sora có thể tạo ra tối đa khoảng 5 phút video mỗi giờ trên mỗi GPU Nvidia H100. So với LLM, suy luận của các mô hình dựa trên khuếch tán như Sora đắt hơn nhiều bậc.
Khi các mô hình giống Sora được triển khai rộng rãi, tính toán suy luận sẽ chiếm ưu thế so với tính toán đào tạo. "Điểm hòa vốn" được ước tính là 15,3-38,1 triệu phút video được tạo ra, sau đó, số lượng tính toán được dành cho suy luận nhiều hơn so với quá trình đào tạo ban đầu. Để so sánh, 17 triệu phút (TikTok) và 43 triệu phút (YouTube) video được tải lên mỗi ngày.
Giả sử việc áp dụng AI đáng kể để tạo video trên các nền tảng phổ biến như TikTok (50% tổng số phút video) và YouTube (15% tổng số phút video) đồng thời tính đến việc sử dụng phần cứng và kiểu sử dụng, chúng tôi ước tính nhu cầu cao nhất là ~ 720 nghìn Nvidia H100 GPU để suy luận.
Tóm lại, Sora thể hiện sự tiến bộ lớn về chất lượng và khả năng tạo video, nhưng cũng có tiềm năng làm tăng đáng kể nhu cầu tính toán suy luận GPU.
Sora là một mô hình phổ biến. Các mô hình Khuếch tán là lựa chọn phổ biến để tạo hình ảnh và các mô hình nổi tiếng như DALL-E của OpenAI hoặc Khuếch tán ổn định của AI ổn định. Gần đây hơn, các công ty như Runway, Genmo và Pika đã khám phá việc tạo video, có thể cũng sử dụng các mô hình phổ biến.

Nói rộng hơn, mô hình khuếch tán là một loại mô hình máy học tổng quát học cách tạo ra dữ liệu giống với dữ liệu mà chúng đã được đào tạo, chẳng hạn như hình ảnh hoặc video, bằng cách dần dần học cách đảo ngược quá trình thêm nhiễu ngẫu nhiên vào dữ liệu. Ban đầu, các mô hình này bắt đầu với một mẫu nhiễu thuần túy và từng bước loại bỏ nhiễu này, tinh chỉnh mẫu cho đến khi nó chuyển thành đầu ra mạch lạc và chi tiết.
Chi tiết kỹ thuật của Sora
OpenAI đã xuất bản một báo cáo kỹ thuật cùng với thông báo về Sora. Thật không may, báo cáo này không có nhiều chi tiết. Tuy nhiên, thiết kế của nó dường như bị ảnh hưởng nặng nề bởi bài nghiên cứu “Mô hình khuếch tán có thể mở rộng với Máy biến áp”, trong đó các tác giả2 đề xuất một kiến trúc dựa trên Máy biến áp có tên là DiT (viết tắt của Máy biến áp khuếch tán) để tạo hình ảnh. Có vẻ như Sora đã mở rộng công việc này sang việc tạo video. Kết hợp cả báo cáo kỹ thuật Sora và bài báo DiT, do đó chúng ta có thể có được một bức tranh khá chính xác về cách hoạt động của mô hình Sora.
Có ba phần quan trọng đối với Sora: 1) Nó không hoạt động trong không gian pixel mà thay vào đó thực hiện khuếch tán trong không gian tiềm ẩn (còn gọi là khuếch tán tiềm ẩn), 2) nó sử dụng kiến trúc Transformer và 3) nó dường như sử dụng một tập dữ liệu rất lớn.
Khuếch tán tiềm ẩn
Để hiểu điểm đầu tiên, khuếch tán tiềm ẩn, hãy xem xét việc tạo ra một hình ảnh. Bạn có thể tạo từng pixel bằng cách sử dụng khuếch tán. Tuy nhiên, điều này rất kém hiệu quả (ví dụ: hình ảnh 512x512 có 262.144 pixel). Thay vào đó, trước tiên bạn có thể ánh xạ từ pixel sang biểu diễn tiềm ẩn với một số hệ số nén, thực hiện khuếch tán trong không gian tiềm ẩn nhỏ gọn hơn này và cuối cùng giải mã trở lại từ không gian tiềm ẩn vào không gian pixel. Ánh xạ này cải thiện đáng kể độ phức tạp tính toán: thay vì phải chạy quá trình khuếch tán trên 512x512 = 262.144 pixel, chẳng hạn, bạn chỉ phải tạo 64x64 = 4.096 tiềm ẩn. Ý tưởng này là bước đột phá quan trọng trong bài nghiên cứu “Tổng hợp hình ảnh độ phân giải cao với các mô hình khuếch tán tiềm ẩn”, là nền tảng của Khuếch tán ổn định.
Minh họa ánh xạ từ pixel (trái) đến biểu diễn tiềm ẩn (lưới hộp ở bên phải). Hình ảnh được lấy từ báo cáo kỹ thuật của Sora.

Cả DiT và Sora đều sử dụng phương pháp này. Đối với Sora, điều cần cân nhắc thêm là video có chiều thời gian: Video là một chuỗi hình ảnh theo thời gian, còn được gọi là khung hình. Từ báo cáo kỹ thuật của Sora, có vẻ như bước mã hóa ánh xạ từ pixel sang không gian tiềm ẩn xảy ra cả về mặt không gian (nghĩa là nén chiều rộng và chiều cao của mỗi khung hình) và theo thời gian (nghĩa là nén theo thời gian).
Máy biến áp
Bây giờ đến điểm thứ hai, cả DiT và Sora đều thay thế kiến trúc U-Net thường được sử dụng bằng kiến trúc Transformer thông thường. Điều này quan trọng vì các tác giả của bài báo DiT nhận thấy rằng việc sử dụng Transformers dẫn đến khả năng mở rộng có thể dự đoán được: Khi bạn áp dụng nhiều tính toán đào tạo hơn (bằng cách đào tạo mô hình lâu hơn hoặc làm cho mô hình lớn hơn hoặc cả hai), bạn sẽ đạt được hiệu suất tốt hơn. Báo cáo kỹ thuật của Sora cũng ghi chú tương tự nhưng dành cho video và bao gồm hình ảnh minh họa hữu ích.
Minh họa cách cải thiện chất lượng mô hình như một chức năng của điện toán đào tạo: điện toán cơ sở, điện toán 4x và điện toán 32x (từ trái sang phải). Video lấy từ báo cáo kỹ thuật của Sora.
Hành vi chia tỷ lệ này, có thể được định lượng bằng cái gọi là luật chia tỷ lệ, là một thuộc tính quan trọng và nó đã được nghiên cứu trước đây trong bối cảnh Mô hình ngôn ngữ lớn (LLM) và cho các mô hình tự hồi quy trên các phương thức khác. Khả năng áp dụng quy mô để có được các mô hình tốt hơn là một trong những động lực chính thúc đẩy sự tiến bộ nhanh chóng của LLM. Vì cùng một thuộc tính tồn tại cho việc tạo hình ảnh và video nên chúng ta có thể mong đợi công thức chia tỷ lệ tương tự cũng sẽ hoạt động ở đây.
Tập dữ liệu
Thành phần quan trọng cuối cùng cần có để đào tạo một người mẫu như Sora là dữ liệu được dán nhãn và chúng tôi nghĩ đây là nơi chứa hầu hết nước sốt bí mật. Để đào tạo mô hình chuyển văn bản thành video như Sora, bạn cần có các cặp video và mô tả bằng văn bản về chúng. OpenAI không nói nhiều về tập dữ liệu của họ nhưng họ gợi ý rằng nó rất lớn: “Chúng tôi lấy cảm hứng từ các mô hình ngôn ngữ lớn có được khả năng tổng quát bằng cách đào tạo trên dữ liệu quy mô internet”. (nguồn). OpenAI đã xuất bản thêm một phương pháp chú thích hình ảnh bằng nhãn văn bản chi tiết, phương pháp này được sử dụng để thu thập bộ dữ liệu DALLE-3. Ý tưởng chung là đào tạo mô hình phụ đề trên tập hợp con được gắn nhãn của tập dữ liệu của bạn và sử dụng mô hình phụ đề đó để tự động gắn nhãn cho phần còn lại. Có vẻ như kỹ thuật tương tự đã được áp dụng cho tập dữ liệu của Sora.
Hàm ý
Chúng tôi tin rằng Sora có một vài ý nghĩa quan trọng. Bây giờ chúng ta sẽ thảo luận ngắn gọn về những điều đó.
Các mô hình video đang bắt đầu thực sự hữu ích
Chất lượng của các video mà Sora có thể tạo ra rõ ràng là một bước đột phá cả về mức độ chi tiết lẫn tính nhất quán về mặt thời gian (ví dụ: mô hình xử lý chính xác tính lâu dài của vật thể khi một vật thể bị che khuất tạm thời và có thể tạo ra phản xạ chính xác trong nước , Ví dụ). Chúng tôi tin rằng chất lượng video hiện đã đủ cho một số loại cảnh nhất định mà chúng có thể được sử dụng trong các ứng dụng trong thế giới thực. Ví dụ: Sora có thể sớm thay thế một số việc sử dụng các đoạn phim video có sẵn.
Tuy nhiên, vẫn còn những thách thức: Hiện tại vẫn chưa rõ mức độ ổn định của các mô hình Sora. Việc chỉnh sửa video được tạo rất khó và tốn thời gian vì mô hình xuất ra pixel. Và việc xây dựng giao diện người dùng và quy trình làm việc trực quan xung quanh các mô hình này cũng là điều cần thiết để làm cho chúng trở nên hữu ích. Các công ty như Runway, Genmo và Pika và nhiều công ty khác (xem bản đồ thị trường ở trên) đã và đang giải quyết những vấn đề này.
Tính năng mở rộng quy mô hoạt động cho các mô hình video nên chúng tôi kỳ vọng tiến độ sẽ nhanh chóng
Thông tin chi tiết quan trọng của bài báo DiT là chất lượng mô hình được cải thiện trực tiếp khi tính toán bổ sung, như đã thảo luận ở trên. Điều này tương tự với các quy luật chia tỷ lệ đã được quan sát đối với LLM. Do đó, chúng ta nên mong đợi sự tiến bộ nhanh chóng hơn nữa về chất lượng của các mô hình tạo video vì những mô hình này được đào tạo với ngày càng nhiều tính toán hơn. Sora là một minh chứng rõ ràng rằng công thức này thực sự hiệu quả và chúng tôi mong đợi OpenAI và những công ty khác sẽ tăng gấp đôi điều này.
Tạo dữ liệu tổng hợp và tăng cường dữ liệu
Trong các lĩnh vực như robot và ô tô tự lái, dữ liệu vốn rất khan hiếm: Không có mạng internet đầy rẫy robot làm nhiệm vụ hoặc ô tô lái. Do đó, thông thường, những vấn đề này được tiếp cận bằng cách đào tạo trong mô phỏng hoặc bằng cách thu thập dữ liệu trên quy mô lớn trong thế giới thực (hoặc kết hợp cả hai). Tuy nhiên, cả hai cách tiếp cận đều gặp khó khăn vì dữ liệu mô phỏng thường không thực tế. Việc thu thập dữ liệu trong thế giới thực trên quy mô lớn rất tốn kém và việc thu thập đủ nhiều dữ liệu cho các sự kiện hiếm gặp là một thách thức.

Chúng tôi tin rằng những mô hình như Sora có thể rất hữu ích ở đây. Chúng tôi nghĩ rằng có thể các mô hình giống Sora có thể được sử dụng để tạo ra dữ liệu tổng hợp hoàn toàn một cách trực tiếp. Sora cũng có thể được sử dụng để tăng cường dữ liệu trong đó video hiện có được chuyển thành các giao diện khác nhau. Điểm thứ hai này được minh họa ở trên khi Sora chuyển đổi video về một chiếc ô tô màu đỏ đang lái trên đường rừng thành khung cảnh rừng rậm tươi tốt. Bạn có thể tưởng tượng việc sử dụng kỹ thuật tương tự để kết xuất lại các cảnh vào ban ngày và ban đêm hoặc để thay đổi điều kiện thời tiết.
Mô phỏng và mô hình thế giới
Một hướng nghiên cứu đầy hứa hẹn là tìm hiểu cái gọi là mô hình thế giới. Nếu đủ chính xác, những mô hình thế giới này cho phép người ta đào tạo các đặc vụ trực tiếp trong chúng hoặc chúng có thể được sử dụng để lập kế hoạch và tìm kiếm.
Có vẻ như những người mẫu như Sora ngầm học cách mô phỏng cơ bản về cách thế giới thực hoạt động trực tiếp từ dữ liệu video. “Mô phỏng mới nổi” này hiện còn thiếu sót nhưng dù sao nó cũng rất thú vị: Nó gợi ý rằng chúng ta có thể đào tạo các mô hình thế giới này ở quy mô lớn từ video. Hơn nữa, Sora dường như có thể mô phỏng những cảnh rất phức tạp như chất lỏng, phản chiếu ánh sáng, vải và chuyển động của tóc. OpenAI thậm chí còn đặt tiêu đề cho báo cáo kỹ thuật của họ là “Các mô hình tạo video như trình mô phỏng thế giới”, điều này cho thấy rõ rằng họ tin rằng đây là khía cạnh quan trọng nhất trong mô hình của họ.
Gần đây, DeepMind đã chứng minh hiệu ứng tương tự với mô hình Genie của họ: Bằng cách chỉ đào tạo trên các video về trò chơi điện tử, mô hình này sẽ học cách mô phỏng các trò chơi này (và nghĩ ra những trò chơi mới). Trong trường hợp này, mô hình thậm chí còn học cách điều kiện hóa các hành động mà không cần quan sát trực tiếp chúng. Một lần nữa, mục tiêu là cho phép học trực tiếp trong các mô phỏng này.
Kết hợp lại, chúng tôi tin rằng các mô hình như Sora và Genie có thể cực kỳ hữu ích để cuối cùng đào tạo các tác nhân hiện thân (ví dụ: trong robot) thực hiện các nhiệm vụ trong thế giới thực ở quy mô lớn. Tuy nhiên, vẫn có những hạn chế: vì các mô hình này được huấn luyện trong không gian pixel nên chúng mô hình hóa mọi chi tiết như cách gió di chuyển lá cỏ, ngay cả khi điều đó hoàn toàn không liên quan đến nhiệm vụ trước mắt. Mặc dù không gian tiềm ẩn bị nén nhưng nó vẫn phải giữ lại nhiều thông tin này vì chúng ta cần có khả năng ánh xạ trở lại pixel, vì vậy không rõ liệu việc lập kế hoạch có thể diễn ra một cách hiệu quả trong không gian tiềm ẩn này hay không.
Tính toán ước tính
Tại Factorial Funds, chúng tôi muốn xem lượng điện toán được sử dụng cho cả mục đích đào tạo và suy luận. Điều này rất hữu ích vì nó có thể đưa ra dự báo về lượng điện toán cần thiết trong tương lai. Tuy nhiên, việc ước tính những số liệu này cũng khó thực hiện vì có rất ít thông tin chi tiết về kích thước mô hình và tập dữ liệu được sử dụng để huấn luyện Sora. Do đó, cần lưu ý rằng các ước tính trong phần này rất không chắc chắn, vì vậy chúng nên được coi nhẹ.
Tính toán ngoại suy đào tạo từ DiT đến Sora
Thông tin chi tiết về Sora rất mỏng nhưng chúng ta có thể xem lại bài báo DiT, đây rõ ràng là nền tảng của Sora và ngoại suy các số liệu tính toán được trình bày ở đó. Mô hình DiT lớn nhất, DiT-XL, có 675M tham số và được đào tạo với tổng ngân sách tính toán khoảng 1021 FLOPS.3 Để làm cho con số này dễ hiểu hơn, con số này tương đương với khoảng 0,4 Nvidia H100 trong 1 tháng (hoặc một chiếc H100 duy nhất). trong 12 ngày).
Bây giờ DiT chỉ làm người mẫu hình ảnh còn Sora là người mẫu video. Sora có thể tạo video dài tối đa 1 phút. Nếu chúng tôi giả sử video được mã hóa ở tốc độ 24 khung hình/giây thì một video bao gồm tối đa 1.440 khung hình. Ánh xạ pixel tới tiềm ẩn của Sora dường như nén cả về mặt không gian và thời gian. Nếu chúng tôi giả sử cùng tốc độ nén từ giấy DiT (8x), chúng tôi sẽ có 180 khung hình trong không gian tiềm ẩn. Vì vậy, chúng tôi thu được hệ số nhân tính toán là 180 lần so với DiT khi ngoại suy nó thành video một cách ngây thơ.
Chúng tôi còn tin rằng Sora lớn hơn đáng kể so với thông số 675M. Chúng tôi ước tính rằng mô hình tham số 20B là khả thi, điều này mang lại cho chúng tôi khả năng tính toán gấp 30 lần so với DiT.
Cuối cùng, chúng tôi tin rằng Sora đã được đào tạo trên tập dữ liệu lớn hơn nhiều so với DiT. DiT đã được huấn luyện cho các bước huấn luyện 3M ở kích thước lô 256, tức là trên tổng số 768 triệu hình ảnh (lưu ý rằng cùng một dữ liệu được lặp lại nhiều lần vì ImageNet chỉ chứa 14 triệu hình ảnh). Sora dường như đã được đào tạo về sự kết hợp giữa hình ảnh và video nhưng ngoài ra chúng tôi hầu như không biết gì về tập dữ liệu. Do đó, chúng tôi đưa ra giả định đơn giản rằng tập dữ liệu của Sora bao gồm 50% hình ảnh tĩnh và 50% video và tập dữ liệu đó lớn hơn 10x-100 lần so với tập dữ liệu được DiT sử dụng. Tuy nhiên, DiT được đào tạo nhiều lần trên cùng một điểm dữ liệu, điều này có thể không tối ưu nếu có sẵn một tập dữ liệu lớn hơn nhiều. Do đó, chúng tôi tin rằng hệ số nhân tính toán từ 4-10 lần là giả định hợp lý hơn.
Kết hợp những điều trên lại với nhau và xem xét cả ước tính thấp và cao cho phép tính tập dữ liệu bổ sung, chúng tôi đi đến phép tính sau:
Ước tính tập dữ liệu thấp: 1021 FLOPS × 30 × 4 × (180 / 2) ≈ 1,1x1025 FLOPS
Ước tính tập dữ liệu cao: 1021 FLOPS × 30 × 10 × (180 / 2) ≈ 2,7x1025 FLOPS
Con số này tương ứng với 4.211 - 10.528 chiếc Nvidia H100 trong 1 tháng.
Suy luận so với tính toán đào tạo
Một điểm cân nhắc quan trọng khác mà chúng tôi có xu hướng xem xét là cách tính toán đào tạo so với tính toán suy luận. Về mặt khái niệm, điện toán đào tạo rất lớn nhưng cũng là chi phí một lần, phát sinh một lần. Ngược lại, tính toán suy luận nhỏ hơn nhiều nhưng được thực hiện cho mỗi thế hệ. Do đó, tính toán suy luận sẽ mở rộng quy mô theo số lượng người dùng và ngày càng trở nên quan trọng khi một mô hình được sử dụng rộng rãi.
Do đó, sẽ rất hữu ích khi xem xét “điểm hòa vốn”, tức là điểm mà tại đó nhiều tính toán được sử dụng cho suy luận hơn là được sử dụng trong quá trình đào tạo.
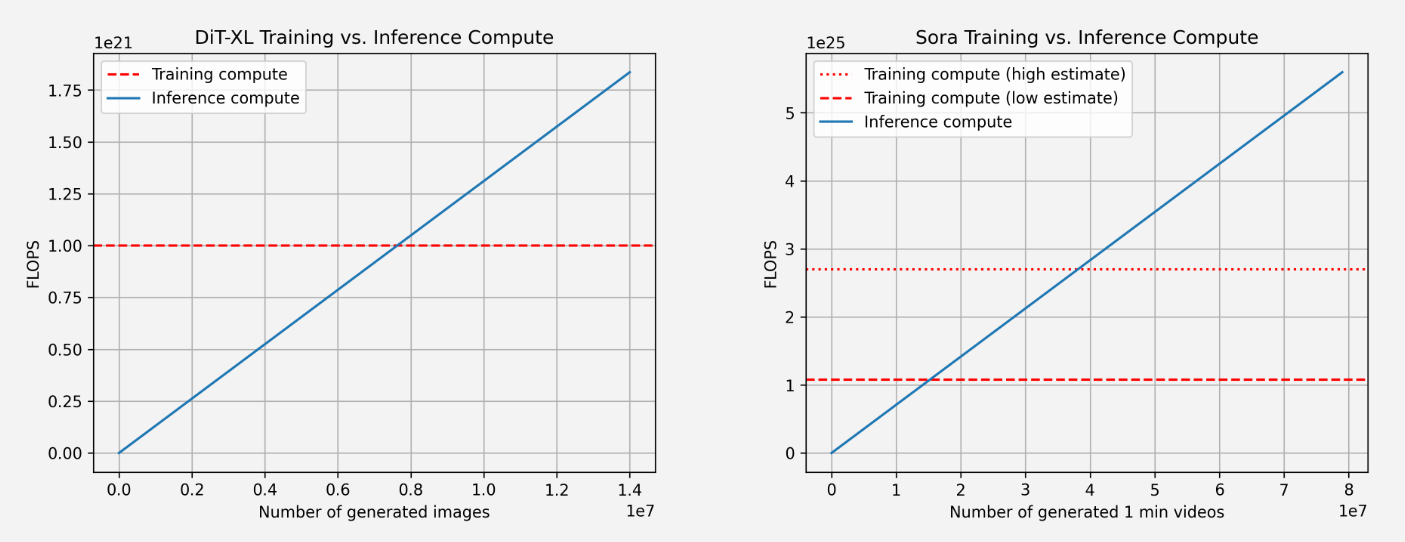
So sánh quá trình đào tạo và tính toán suy luận cho DiT (trái) và Sora (phải). Đối với Sora, dữ liệu của chúng tôi dựa trên ước tính trên và do đó không hoàn toàn đáng tin cậy. Chúng tôi cũng hiển thị hai ước tính cho điện toán đào tạo: một ước tính thấp (giả sử hệ số nhân gấp 4 lần cho kích thước tập dữ liệu) và ước tính cao (giả sử hệ số nhân gấp 10 lần cho kích thước tập dữ liệu).
Đối với các số liệu trên, chúng tôi lại sử dụng DiT để ngoại suy cho Sora. Đối với DiT, mô hình lớn nhất (DiT-XL) sử dụng 524×109 FLOPS mỗi bước và DiT sử dụng 250 bước khuếch tán để tạo ra một hình ảnh duy nhất, với tổng số 131×1012 FLOPS. Chúng ta có thể thấy rằng điểm hòa vốn đạt được sau khi tạo ra 7,6 triệu hình ảnh, sau đó tính toán suy luận chiếm ưu thế. Để tham khảo, người dùng tải khoảng 95 triệu hình ảnh mỗi ngày lên Instagram (nguồn).
Đối với Sora, chúng tôi ngoại suy FLOPS thành 524×109 FLOPS × 30 × 180 ≈ 2,8×1015 FLOPS. Nếu chúng tôi vẫn giả sử 250 bước khuếch tán cho mỗi video thì đó là tổng cộng 708×1015 FLOPS cho mỗi video. Để tham khảo, tức là khoảng 5 phút video được tạo trên mỗi Nvidia H100 mỗi giờ.5 Điểm hòa vốn đạt được sau 15,3 triệu (thấp) đến 38,1 triệu (cao) phút video được tạo, sau đó có nhiều suy luận hơn là tính toán đào tạo đã tiêu. Để tham khảo, khoảng 43 triệu phút video được tải lên YouTube mỗi ngày (nguồn).
Một số lưu ý: Đối với suy luận, FLOPS không phải là khía cạnh duy nhất quan trọng đối với suy luận. Ví dụ, băng thông bộ nhớ là một yếu tố quan trọng khác. Hơn nữa, có nghiên cứu tích cực về việc giảm số bước khuếch tán, dẫn đến khả năng tính toán ít hơn và do đó suy luận nhanh hơn nhiều. Tỷ lệ sử dụng FLOPS cũng có thể khác nhau giữa huấn luyện và suy luận, trong trường hợp đó chúng trở nên quan trọng cần xem xét.
Tính toán suy luận trên các mô hình khác nhau
Chúng tôi cũng xem xét cách hoạt động của tính toán suy luận trên mỗi đơn vị đầu ra trên các mô hình khác nhau cho các phương thức khác nhau. Ý tưởng ở đây là để xem mức độ suy luận chuyên sâu về điện toán đối với các loại mô hình khác nhau, điều này có ý nghĩa ngay lập tức đối với việc lập kế hoạch và nhu cầu điện toán. Điều quan trọng là phải hiểu rằng đơn vị đầu ra thay đổi đối với từng kiểu máy vì chúng hoạt động ở các phương thức khác nhau: Đối với Sora, một đầu ra là một video dài 1 phút, đối với DiT là một hình ảnh 512x512px duy nhất và đối với Llama 2 và GPT-4 chúng tôi xác định một đầu ra duy nhất là một tài liệu gồm 1.000 mã thông báo văn bản.

So sánh khả năng tính toán suy luận theo mô hình trên mỗi đơn vị đầu ra (đối với Sora, video 1 phút, đối với GPT-4 và LLama 2 1000 mã thông báo văn bản và đối với DiT một hình ảnh 512x512px). Chúng ta có thể thấy rằng ước tính của chúng ta về suy luận của Sora là đắt hơn nhiều về mặt tính toán.
Chúng tôi so sánh Sora, DiT-XL, LLama 2 70B và GPT-4 và vẽ đồ thị cho chúng với nhau (sử dụng thang đo log cho FLOPS). Đối với Sora và DiT, chúng tôi sử dụng các ước tính suy luận ở trên. Đối với Llama 2 và GPT-4, chúng tôi ước tính số lượng FLOPS bằng cách sử dụng công thức quy tắc ngón tay cái của FLOPS = 2 × số tham số × số lượng mã thông báo được tạo. Đối với GPT-4, chúng tôi giả định mô hình này là mô hình Hỗn hợp các chuyên gia (MoE) với 220B tham số / chuyên gia và 2 chuyên gia hoạt động trên mỗi lượt chuyển tiếp (nguồn). Lưu ý rằng đối với GPT-4, những số liệu này không được OpenAI xác nhận, vì vậy chúng một lần nữa cần được coi trọng.
Chúng ta có thể thấy rằng suy luận đối với các mô hình dựa trên khuếch tán như DiT và Sora đắt hơn nhiều: DiT-XL (mô hình có 675M) tiêu thụ lượng điện toán suy luận gần tương đương với LLama 2 (mô hình có tham số 70B). Chúng ta có thể thấy thêm rằng Sora đắt hơn nhiều so với GPT-4 đối với khối lượng công việc suy luận.
Điều quan trọng cần lưu ý là nhiều số liệu trên là ước tính và dựa trên các giả định đơn giản hóa. Ví dụ: chúng không tính đến việc sử dụng FLOPS thực tế của GPU, các hạn chế xung quanh dung lượng bộ nhớ và băng thông bộ nhớ cũng như các kỹ thuật nâng cao như giải mã suy đoán.
Tính toán suy luận nếu các mô hình giống Sora đạt được thị phần đáng kể
Trong phần này, chúng tôi ngoại suy từ các yêu cầu tính toán của Sora để xem cần bao nhiêu Nvidia H100 để chạy các mô hình giống Sora ở quy mô đáng kể, nghĩa là các video do AI tạo ra sẽ có khả năng thâm nhập thị trường đáng kể trên các nền tảng video phổ biến như TikTok và YouTube.
Chúng tôi giả định 5 phút video được sản xuất trên mỗi Nvidia H100 mỗi giờ (xem chi tiết ở trên), tương đương với 120 phút video trên mỗi H100 mỗi ngày
TikTok: 17 triệu phút video mỗi ngày (tổng cộng 34 triệu video × thời lượng trung bình là 30 giây), giả sử AI có mức độ thâm nhập 50% (nguồn)
YouTube: 43 triệu phút video mỗi ngày, giả sử AI thâm nhập 15% (chủ yếu là video dưới 2 phút)
Tổng số video được AI sản xuất hàng ngày: 8,5 triệu + 6,5 triệu = 10,7 triệu phút
Tổng Nvidia H100 cần thiết để hỗ trợ cộng đồng người sáng tạo trên TikTok & YouTube: 10,7M / 120 ≈ 89k
Con số này có thể quá thấp do có nhiều yếu tố cần được tính đến:
Chúng tôi giả định việc sử dụng FLOPS 100% và không xem xét các tắc nghẽn về bộ nhớ và giao tiếp. Trong thực tế, việc sử dụng 50% là thực tế hơn, tức là tăng hệ số gấp 2 lần.
Nhu cầu không được phân bổ đồng đều theo thời gian mà thay vào đó là sự bùng nổ. Nhu cầu cao nhất đặc biệt có vấn đề vì bạn cần nhiều GPU hơn để vẫn phục vụ mọi lưu lượng truy cập. Chúng tôi cho rằng nhu cầu cao nhất sẽ bổ sung thêm hệ số gấp 2 lần nữa để có số lượng GPU tối đa cần thiết.
Người sáng tạo có thể sẽ tạo nhiều video ứng cử viên để chọn ra video hay nhất trong số những ứng cử viên này. Chúng tôi đưa ra giả định thận trọng rằng trung bình có 2 ứng cử viên cho mỗi video tải lên được tạo ra, điều này làm tăng thêm hệ số khác là 2x.
Tổng cộng điều này khiến chúng ta có ~720k GPU Nvidia H100 ở mức cao nhất
Điều này chứng tỏ niềm tin của chúng tôi rằng tính toán suy luận sẽ chiếm ưu thế khi các mô hình AI tổng quát ngày càng trở nên phổ biến và đáng tin cậy. Đối với các mô hình dựa trên sự khuếch tán như Sora, thậm chí còn hơn thế.
Cũng lưu ý rằng việc mở rộng mô hình sẽ làm tăng thêm đáng kể nhu cầu tính toán suy luận. Mặt khác, một số điều này có thể được khắc phục bằng các kỹ thuật suy luận được tối ưu hóa hơn và các tối ưu hóa khác trên toàn bộ ngăn xếp.
Theo Factorial Funds